I have found that I get data from many different sources. These sources range from simple .csv files to more complex relational databases, to structure XML or JSON files. I have compiled the different approaches that one can use to easily access these datasets.
Local Column Delimited Files
This is probably the most common and easiest approach to load data into R. It simply requires one line to do everything that is needed to set up the data. Then a couple additional lines to tidy up the dataset.
file <- "c:\\my_folder\\my_file.txt" raw_data <- read.csv(file, sep=","); ##'sep' can be a number of options including \t for tab delimited names(raw_data) <- c("VAR1","VAR2","RESPONSE1") [/sourcecode] Text File From the Internet
I find this very useful when I need to get datasets from a Web site. This is particularly useful if I need to rerun the script and the Web site continually updates their data. This save me from having to download the dataset into a csv file each time I need to run an update. In this example I use one of my favorite data sources which comes from the National Data Buoy Center. This example pulls data from a buoy (buoy #44025) off the coast of New Jersey. Conveniently you can use the same read.csv() function that you would use if read the file from you own computer. You simply replace the file location with the URL of the data.
file <- "http://www.ndbc.noaa.gov/view_text_file.php?filename=44025h2011.txt.gz&dir=data/historical/stdmet/”
raw_data <- read.csv(file, header=T, skip=1) [/sourcecode] Files From Other Software
Often I will have Excel files, SPSS files, or SAS dataset set to me. Once again I can either export the data as a csv file and then import using the read.csv function. However, taking that approach every time means that there is an additional step. By adding unnecessary steps to a process increases the risk that the data might get corrupted due to human error. Furthermore, if the data is updated from time to time then the data that you downloaded last week may not have the most current data.
SPSS
library(foreign)
file <- "C:\\my_folder\\my_file.sav"
raw <- as.data.frame(read.spss(file))
[/sourcecode]
Microsoft Excel
library(XLConnect)
file <- "C:\\my_folder\\my_file.xlsx" raw_wb <- loadWorkbook(file, create=F) raw <- as.data.frame( readWorksheet(raw_wb, sheet='Sheet1') ) [/sourcecode] Data From Relational Databases
There is the RMySQL library which is very useful. However, I have generally been in the habit of using the RODBC library. The reason for this is that I will often jump between databases (e.g. Oracle, MSSQL, MySQL). By using the RODBC library I can keep all of my connections in one location and use the same functions regardless of the databases. This example below will work on any standard SQL database. You just need to make sure you set up an ODBC connection call (in this example) MY_DATABASE.
library(RODBC)
channel <- odbcConnect("MY_DATABASE", uid="username", pwd="password")
raw <- sqlQuery(channel, "SELECT * FROM Table1");
[/sourcecode]
Data from Non-Relational Databases
R has the capability to pull data from non-relational databases. These include Hadoop (rhbase), Cassandra (RCassandra), MongoDB (rmongodb). I personally have not used RCassandra but here is the documentation. The example here uses MongoDB using an example provided by MongoDB.
library(rmongodb)
MyMongodb <- "test"
ns <- "articles"
mongo <- mongo.create(db=MyMmongodb)
list.d <- mongo.bson.from.list(list(
"_id"="wes",
name=list(first="Wesley", last=""),
sex="M",
age=40,
value=c("7", "5","8","2")
))
mongo.insert(mongo, "test.MyPeople", list.d)
list.d2 <- mongo.bson.from.list(list(
"_id"="Article1",
when=mongo.timestamp.create(strptime("2012-10-01 01:30:00",
"%Y-%m-%d %H:%M:%s"), increment=1),
author="wes",
title="Importing Data Into R from Different Sources",
text="Provides R code on how to import data into R from different sources.",
tags=c("R", "MongoDB", "Cassandra","MySQL","Excel","SPSS"),
comments=list(
list(
who="wes",
when=mongo.timestamp.create(strptime("2012-10-01 01:35:00",
"%Y-%m-%d %H:%M:%s"), increment=1),
comment="I'm open to comments or suggestions on other data sources to include."
)
)
)
)
list.d2
mongo.insert(mongo, "test.MyArticles", list.d2)
res <- mongo.find(mongo, "test.MyArticles", query=list(author="wes"), fields=list(title=1L))
out <- NULL
while (mongo.cursor.next(res)){
out <- c(out, list(mongo.bson.to.list(mongo.cursor.value(res))))
}
out
[/sourcecode]
Copied and Pasted Text
raw_txt <- " STATE READY TOTAL AL 36 36 AK 5 8 AZ 15 16 AR 21 27 CA 43 43 CT 56 68 DE 22 22 DC 7 7 FL 130 132 GA 53 54 HI 11 16 ID 11 11 IL 24 24 IN 65 77 IA 125 130 KS 22 26 KY 34 34 LA 27 34 ME 94 96 MD 25 26 MA 82 92 Mi 119 126 MN 69 80 MS 43 43 MO 74 82 MT 34 40 NE 9 13 NV 64 64 NM 120 137 NY 60 62 NJ 29 33 NH 44 45 ND 116 135 NC 29 33 OH 114 130 OK 19 22 PA 101 131 RI 32 32 Sc 35 45 SD 25 25 TN 30 34 TX 14 25 UT 11 11 VT 33 49 VA 108 124 WV 27 36 WI 122 125 WY 12 14 " raw_data <- textConnection(raw_txt) raw <- read.table(raw_data, header=TRUE, comment.char="#", sep="") close.connection(raw_data) raw ###Or the following line can be used raw <- read.table(header=TRUE, text=raw_txt) [/sourcecode] Structured Local or Remote Data
One feature that I find quite useful is when there is a Web site with a table that I want to analyze. R has the capability to read through the HTML and import the table that you want. This example uses the XML library and pulls down the population by country in the world. Once the data is brought into R it may need to be cleaned up a bit removing unnecessary columns and other stray characters. The examples here use remote data from other Web sites. If the data is available as a local file then it can be imported in a similar fashion just using filename rather than the URL.
library(XML)
url <- "http://en.wikipedia.org/wiki/List_of_countries_by_population" population = readHTMLTable(url, which=3) population [/sourcecode] Or you can use the feature to simple grab XML content. I have found this particularly useful when I need geospatial data and need to get the latitude/longitude of a location (this example uses Open Street Maps API provided by MapQuest). This example obtains the results for the coordinates of the United States White House. [sourcecode language="css"] url <- "http://open.mapquestapi.com/geocoding/v1/address?location=1600%20Pennsylvania%20Ave,%20Washington,%20DC&outFormat=xml" mygeo <- xmlToDataFrame(url) mygeo$result [/sourcecode] An alternate approach is to use a JSON format. I generally find that JSON is a better format and it can be readily used in most programming languages. [sourcecode language="css"] library(rjson) url <- "http://open.mapquestapi.com/geocoding/v1/address?location=1600%20Pennsylvania%20Ave,%20Washington,%20DC&outFormat=json" raw_json <- scan(url, "", sep="\n") mygeo <- fromJSON(raw_json) [/sourcecode]



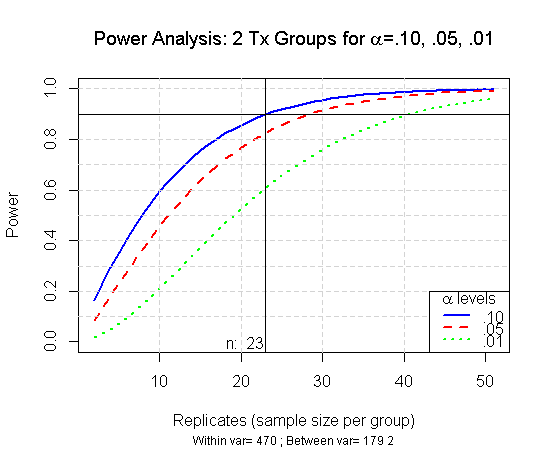
 and power is calculated as
and power is calculated as  .
. ,
,  ,
,  , and
, and  (probability of a Type I error). Normally, if a researcher already knows the population mean (
(probability of a Type I error). Normally, if a researcher already knows the population mean (=P\left(Z>\frac{38-50}{10}\right)=P\left(Z>-1.2\right)=.8849303")


 ) a sample of size 23 (per group) is needed. So that will be a total of 46 observations. It’s then up to the researcher to determine the appropriate sample size based on needed power, desired effect size,
) a sample of size 23 (per group) is needed. So that will be a total of 46 observations. It’s then up to the researcher to determine the appropriate sample size based on needed power, desired effect size, 



 . That is a fairly large number but it just not large enough. That is particularly true if that number is a phone number (e.g. (214)748-3647). As you can see there would be a large block of numbers that would cause problems. In other words a phone number is not an integer and should not be cast as an integer, ever! Normally on 32-bit systems if an integer exceeds that number it will either kindly return an error or it will send you back in time to the year 1901. Neither one of those options are very good. The solution: upgrade to a 64-bit system. That will allow for a maximum integer of 9,223,372,036,854,775,807. A 64-bit system will be good for another 292 million years. The time solution is then solved. However, it’s not out of the question that there could be a scenario when a researcher will exceed 9.2 quintillion. This could be the case when dealing with large data mining and trying to analyze something like each grain of sand on a beach. But I guess then it’s time to upgrade again to something bigger.
. That is a fairly large number but it just not large enough. That is particularly true if that number is a phone number (e.g. (214)748-3647). As you can see there would be a large block of numbers that would cause problems. In other words a phone number is not an integer and should not be cast as an integer, ever! Normally on 32-bit systems if an integer exceeds that number it will either kindly return an error or it will send you back in time to the year 1901. Neither one of those options are very good. The solution: upgrade to a 64-bit system. That will allow for a maximum integer of 9,223,372,036,854,775,807. A 64-bit system will be good for another 292 million years. The time solution is then solved. However, it’s not out of the question that there could be a scenario when a researcher will exceed 9.2 quintillion. This could be the case when dealing with large data mining and trying to analyze something like each grain of sand on a beach. But I guess then it’s time to upgrade again to something bigger. .
.

