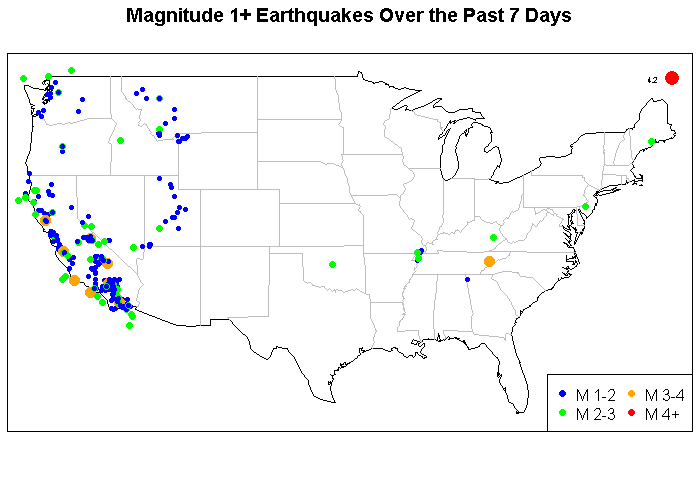
This is a brief example using the maps in R and to highlight a source of data. This is real-time data and it comes from the U.S. Geological Survey. This shows the location of earthquakes with magnitude of at least 1.0 in the lower 48 states.
library(maps)
library(maptools)
library(rgdal)
eq = read.table(file=”http://earthquake.usgs.gov/earthquakes/catalogs/eqs7day-M1.txt”, fill=TRUE, sep=”,”, header=T)
plot.new()
my.map <- map("state", interior = FALSE, plot=F)
x.lim <- my.map$range[1:2]; x.lim[1] <- x.lim[1]-1; x.lim[2] <- x.lim[2]+1;
y.lim <- my.map$range[3:4]; y.lim[1] <- y.lim[1]-1; y.lim[2] <- y.lim[2]+1;
map("state", interior = FALSE, xlim=x.lim, ylim=y.lim)
map("state", boundary = FALSE, col="gray", add = TRUE)
title("Magnitude 1+ Earthquakes Over the Past 7 Days")
eq$mag.size <- NULL
eq$mag.size[eq$Magnitude>=1 & eq$Magnitude<2] <- .75
eq$mag.size[eq$Magnitude>=2 & eq$Magnitude<3] <- 1.0
eq$mag.size[eq$Magnitude>=3 & eq$Magnitude<4] <- 1.5
eq$mag.size[eq$Magnitude>=4] <- 2.0
eq$mag.col <- NULL
eq$mag.col[eq$Magnitude>=1 & eq$Magnitude<2] <- 'blue'
eq$mag.col[eq$Magnitude>=2 & eq$Magnitude<3] <- 'green'
eq$mag.col[eq$Magnitude>=3 & eq$Magnitude<4] <- 'orange'
eq$mag.col[eq$Magnitude>=4] <- 'red'
points(x=eq$Lon,y=eq$Lat,pch=16,cex=eq$mag.size, col=eq$mag.col)
eq$magnitude.text <- eq$Magnitude
eq$magnitude.text[eq$Magnitude<4] <- NA
text(x=eq$Lon,y=eq$Lat,col='black',labels=eq$magnitude.text,adj=c(2.5),cex=0.5)
legend('bottomright',c('M 1-2','M 2-3','M 3-4','M4+'), ncol=2,
pch=16, col=c('blue','green','orange','red'))
box()
[/sourcecode]



 . That is a fairly large number but it just not large enough. That is particularly true if that number is a phone number (e.g. (214)748-3647). As you can see there would be a large block of numbers that would cause problems. In other words a phone number is not an integer and should not be cast as an integer, ever! Normally on 32-bit systems if an integer exceeds that number it will either kindly return an error or it will send you back in time to the year 1901. Neither one of those options are very good. The solution: upgrade to a 64-bit system. That will allow for a maximum integer of 9,223,372,036,854,775,807. A 64-bit system will be good for another 292 million years. The time solution is then solved. However, it’s not out of the question that there could be a scenario when a researcher will exceed 9.2 quintillion. This could be the case when dealing with large data mining and trying to analyze something like each grain of sand on a beach. But I guess then it’s time to upgrade again to something bigger.
. That is a fairly large number but it just not large enough. That is particularly true if that number is a phone number (e.g. (214)748-3647). As you can see there would be a large block of numbers that would cause problems. In other words a phone number is not an integer and should not be cast as an integer, ever! Normally on 32-bit systems if an integer exceeds that number it will either kindly return an error or it will send you back in time to the year 1901. Neither one of those options are very good. The solution: upgrade to a 64-bit system. That will allow for a maximum integer of 9,223,372,036,854,775,807. A 64-bit system will be good for another 292 million years. The time solution is then solved. However, it’s not out of the question that there could be a scenario when a researcher will exceed 9.2 quintillion. This could be the case when dealing with large data mining and trying to analyze something like each grain of sand on a beach. But I guess then it’s time to upgrade again to something bigger. .
.
